网络爬虫程序
编辑:Simone
2025-05-16 23:10:05
600 阅读
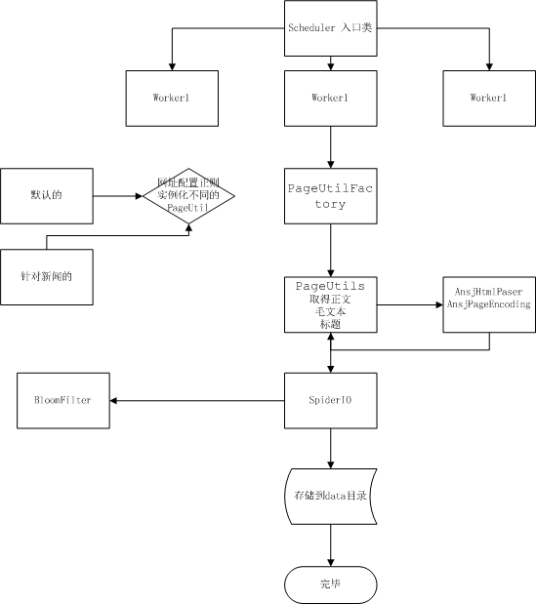
Spider又叫WebCrawler或者Robot,是一个沿着链接漫游Web 文档集合的程序。它一般驻留在服务器上,通过给定的一些URL,利用HTTP等标准协议读取相应文档,然后以文档中包括的所有未访问过的URL作为新的起点,继续进行漫游,直到没有满足条件的新URL为止。WebCrawler的主要功能是自动从Internet上的各Web 站点抓取Web文档并从该Web文档中提取一些信息来描述该Web文档,为搜索引擎站点的数据库服务器追加和更新数据提供原始数据,这些数据包括标题、长度、文件建立时间、HTML文件中的各种链接数目等。
想要了解更多“网络爬虫程序”的信息,请点击:网络爬虫程序百科
版权声明:本站【问百科】文章素材来源于网络或者用户投稿,未经许可不得用于商用,如转载保留本文链接:https://www.wenbaik.com/life/398686.html